-
Pairs Trading: The Math behind the Code
However, the results of the cointegration/augmented Dickey Fuller test indicates the following.

The t-statistic of this test is – 1.9416 which is way lesser than the 90% threshold and we can safely assume that this pair is NOT cointegrated. The hedge ratio is 1.8053 but this does not seem to be a good candidate for pairs trading. Going based on correlation alone would have been the wrong move!
Now, let’s look at two other stocks ( SPY and QCOM) again over the past 3 years and run the same cointegration test.
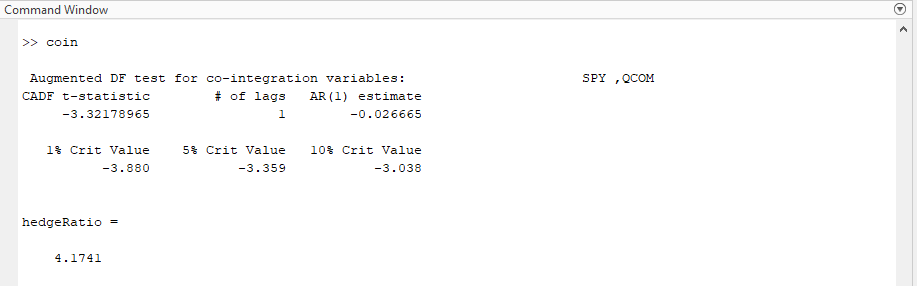
As you can see the t-statistic is a much better -3.3217 which implies a more than 90% probability that the two time series are co-integrated. This would need more validation before putting on the trade at a hedge ratio of 4.174 but definitely seems more promising than the previous pair.
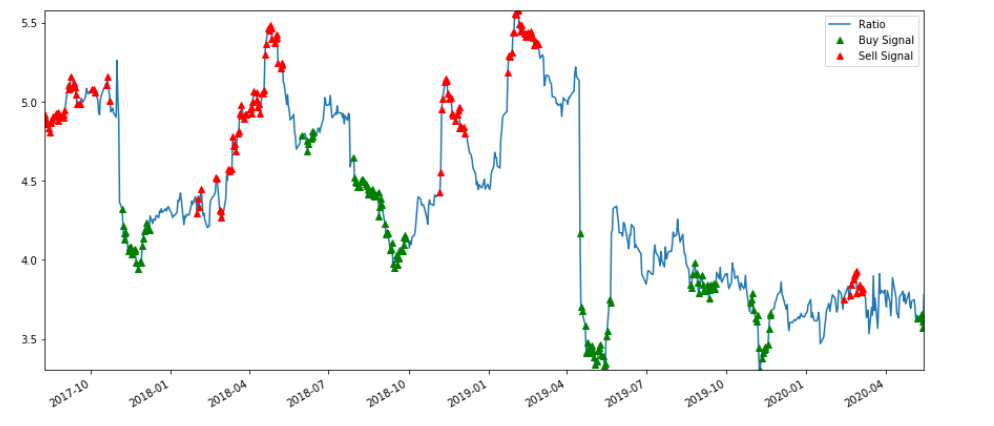
I will not go into generating specific trading signals because that exercise is very nuanced and there are several attributes to consider including training/testing the data set and specific signaling algorithms. However, as a very simplistic illustration, the chart below indicates the z-score based buy and sell signals for the SPY/QCOM pair based on the assumption that the ratio reverts to the mean. The trading signals are generated from a measure of the rolling mean (60 day Moving Average) and (60 day standard deviation). The z score is (5 day moving average – 60 day moving average) divided by (60 day standard deviation). Though this set up looks promising, this needs to be validated further.